

اتوماسیون گردش کار اسناد با هوش مصنوعی: ترکیب RPA و NLP برای بهینهسازی فرآیندها
1. مقدمه 🎯
– 📄 مقدمهای بر چالشهای گردش کار اسناد سنتی
در شکل سنتی، گردش کار اسناد مبتنی بر عملیات دستی است: دریافت فیزیکی برگهها، پر کردن فرمها، امضا و بایگانی کاغذی. این فرایندها معمولاً منجر به اتلاف زمان و عدم شفافیت در پیگیری وضعیت پروندهها میشوند ⏳.
وجود احتمال بروز خطاهای انسانی مثل اشتباه در ثبت اطلاعات یا گمشدن مدارک، هزینهبر و پرریسک است 🛑. جستجو در بین قفسههای کاغذی و ارسال فیزیکی مدارک بین واحدها نیز سرعت تصمیمگیری را بهطور چشمگیری کاهش میدهد 🕵️♂️.
با توجه به این چالشها، اتوماسیون گردش کار اسناد بهعنوان راهکاری ضروری برای هوشمندسازی فرایندها و حذف فعالیتهای تکراری مطرح میشود 🤖. در ادامه، بررسی میکنیم چگونه ترکیب RPA و NLP میتواند سطح جدیدی از کارایی و دقت را فراهم آورد ✨.
2. تعریف گردش کار اسناد (Document Workflow) 🗂️
– مراحل اصلی گردش کار اسناد
1. ایجاد (Capture) 📥
دریافت یا اسکن سند اولیه و ثبت متادیتا (تاریخ، نویسنده، نوع سند). در اتوماسیون گردش کار اسناد، ورودیهای دستی با اسکنرهای هوشمند و فرمهای وب جایگزین میشوند.
2. دستهبندی (Classification) 🏷️
تعیین گروهبندی سند بر اساس محتوا (مالی، حقوقی، پرسنلی) و برچسبگذاری برای تسهیل جستجو. با استفاده از پردازش زبان طبیعی، دستهبندی خودکار با دقت بالاتر انجام میگیرد.
3. توزیع (Routing) 🔄
انتقال دیجیتال سند به کاربر یا واحد مسئول مرحله بعدی. اتوماسیون گردش کار اسناد، ارسال خودکار اعلانها و دسترسیهای لازم را بدون دخالت نیروی انسانی انجام میدهد.
4. پردازش (Processing) 🤖
استخراج اطلاعات کلیدی (مثل کدملی، شماره فاکتور) و تکمیل فیلدهای مورد نیاز سیستمهای داخلی با RPA و NLP. این مرحله سرعت انجام امور را چندین برابر میکند.
5. بازبینی و تأیید (Review & Approval) ✔️
بررسی محتوا توسط مسئول و تأیید یا درخواست اصلاح. در محیطهای اتوماسیون گردش کار اسناد، کارتابل الکترونیک با امکان نظرات، امضا دیجیتال و تاریخچه تغییرات ارائه میشود.
6. ذخیرهسازی (Archiving) 📦
انتقال نهایی سند به مخزن دیجیتال یا سیستم مدیریت اسناد سازمان. فرمتهای قابل جستجو (PDF/A، XML) و ساختار پوشهبندی خودکار، فضای بایگانی را بهینه میکنند.
7. نظارت و گزارشگیری (Monitoring & Reporting) 📊
ردیابی وضعیت هر سند در هر مرحله با داشبورد و گزارشهای لحظهای. شاخصهای کلیدی عملکرد (KPI) مانند زمان گردش، تعداد بازگشتها و نرخ خطا، برای بهبود مداوم فرآیندها تحلیل میشوند.
—
این ساختار نهتنها چشماندازی شفاف از گردش کار اسناد ارائه میدهد، بلکه با اتوماسیون گردش کار اسناد سطح جدیدی از دقت، سرعت و پاسخگویی به نیازهای کسبوکارها فراهم میکند.
3. فناوری RPA در مدیریت اسناد 🤖
– خودکارسازی تکرار کارها و فواید آن تعریف RPA
Robotic Process Automation (RPA) تکنولوژی نرمافزاری است که امکان شبیهسازی و اجرای خودکار کارهای تکراری و مبتنی بر قوانین را در سیستمهای اطلاعاتی فراهم میکند. با RPA میتوان فرآیندهای دست به قلم از قبیل ورود داده، استخراج اطلاعات و انتقال فایل را بدون نیاز به دخالت انسان انجام داد.
خودکارسازی وظایف تکراری
این فناوری بهخصوص در مدیریت اسناد، باعث حذف کامل مراحل خستهکننده و زمانبر میشود. مثالهایی از وظایفی که RPA میتواند خودکار کند:
– 📥 دریافت و اسکن اتوماتیک اسناد ورودی
– 🗂️ استخراج فیلدهای کلیدی (تاریخ، نام، شماره فاکتور)
– 🔄 انتقال خودکار فایلها بین پوشهها و سیستمهای مدیریتی
– ✉️ ارسال اعلان و یادآوری پایان فرایند برای تیمهای درگیر
فواید کلیدی استفاده از RPA در گردش کار اسناد
1. ⏱ صرفهجویی در زمان
اتوماسیون گردش کار اسناد با RPA میتواند تا 80٪ زمان فرایندهای دستی را کاهش دهد.
2. ✅ افزایش دقت
حذف خطاهای انسانی در ثبت و انتقال دادهها، باعث کیفیت بالاتر اطلاعات میشود.
3. 💰 کاهش هزینهها
کاهش نیروی انسانی مورد نیاز برای عملیات تکراری، هزینههای عملیاتی را بهطور چشمگیری پایین میآورد.
4. 📈 مقیاسپذیری
با افزایش حجم اسناد، رباتهای نرمافزاری بهسادگی قابل کپی و پیادهسازی روی سرورهای جدید هستند.
5. 🔍 شفافیت و ردیابی
هر مرحله از گردش کار بهصورت خودکار گزارش و لاگ میشود و داشبوردهای مدیریتی گزارشهای لحظهای در اختیار مدیران قرار میدهد.
مراحل پیادهسازی RPA
– تحلیل گردش کار فعلی
– طراحی و توسعه ربات برای هر وظیفه تکراری
– تست و اعتبارسنجی عملکرد ربات
– استقرار در محیط تولید و مانیتورینگ مستمر
– بهینهسازی مستمر براساس شاخصهای کلیدی عملکرد (KPI)
—
با بهکارگیری فناوری RPA در مدیریت اسناد، نهتنها سرعت و دقت در اتوماسیون گردش کار اسناد بهطرز چشمگیری افزایش مییابد، بلکه سازمان شما قادر خواهد بود منابع انسانی و مالی را به پروژههای استراتژیکتر اختصاص دهد.
4. پردازش زبان طبیعی (NLP) برای استخراج معنا از متون 🧠
- چگونگی تحلیل خودکار متون فارسی و انگلیسی
تعریف پردازش زبان طبیعی
پردازش زبان طبیعی مجموعه روشها و الگوریتمهایی است که به کامپیوترها اجازه میدهد زبان انسانی را بفهمند، تجزیه و تحلیل کنند و معنای آن را استخراج کنند. مهمترین وظایف NLP شامل بخشبندی (tokenization)، تشخیص نقش کلمات (POS tagging)، یافتن موجودیتهای نامدار (NER) و تحلیل احساسات (sentiment analysis) است.
مراحل تحلیل خودکار متون فارسی
- نرمالسازی و پیشپردازش
- اصلاح املایی، یکنواختسازی کلمات (مثل «ی» و «ي»)، حذف نویسههای غیرمرتبط.
- بخشبندی و توکنسازی
- تبدیل متن به واحدهای معنایی (توکن) با توجه به فاصله و نشانهها.
- حذف توقفکلمات و ریشهیابی
- کنار گذاشتن کلماتی مثل «از»، «به»، «و» و یافتن ریشه هر کلمه.
- تبدیل به ویژگی (Feature Extraction)
- استفاده از مدلهایی مانند FastText یا ParsBERT برای تبدیل توکنها به بردارهای عددی.
- شناسایی موجودیتها و مفاهیم
- اجرای الگوریتمهای NER سفارشی یا از پیشآموزشدیده برای پیدا کردن نام افراد، سازمانها و تاریخها.
- طبقهبندی و خوشهبندی
- تشخیص موضوع سند با مدلهای یادگیری ماشین (مثلاً LSTM یا Transformer)
- استخراج روابط ساختاری
- بهرهگیری از تحلیل نحوی (dependency parsing) برای فهم روابط بین کلمات کلیدی
مراحل تحلیل خودکار متون انگلیسی
- توکنسازی با ابزار استاندارد (NLTK، spaCy)
- حذف توقفکلمات و lemmatization
- ویژگییابی با word embeddings (Word2Vec, GloVe) یا مدلهای Transformer (BERT, RoBERTa)
- اجرای NER و POS tagging با spaCy یا Stanford NLP
- تحلیل احساسات یا تشخیص موضوع با مدلهای پیشآموزشدیده
- تولید خروجی ساختیافته (JSON یا XML) برای مراحل بعدی گردش کار اسناد
تکنیکهای کلیدی استخراج معنا
- Named Entity Recognition (NER): یافتن و برچسبگذاری اسامی افراد، مکانها و سازمانها
- Sentiment Analysis: تشخیص نگرش مثبت، منفی یا خنثی در متن
- Topic Modeling: استخراج موضوعات کلیدی با LDA یا BERTopic
- Dependency Parsing: تحلیل ساختار نحوی و روابط دستوری
- Semantic Similarity: اندازهگیری شباهت معنایی بین بخشهای مختلف متن
ابزارها و کتابخانههای رایج
- برای متن فارسی:
- Hazm / Parsivar (توکنسازی و ریشهیابی)
- ParsBERT (بردارهای زبان فارسی)
- Stanza (پشتیبانی محدود فارسی)
- برای متن انگلیسی:
- spaCy / NLTK (پیشپردازش و NER)
- Hugging Face Transformers (BERT، RoBERTa)
- Gensim (Topic Modeling)
نکات ترکیب NLP با گردش کار اسناد
- فراخوانی مدل NLP بهصورت سرویس REST از داخل فلوچارت RPA
- تنظیم قوانین خودکار: مثلاً اگر موجودیت «تاریخ انقضا» شناسایی شد، مرحله ارجاع به واحد مالی فعال شود
- ذخیره نتایج تحلیل (موجودیتها، برچسبها) در فیلدهای سیستم مدیریت اسناد
- مانیتورینگ و لاگبرداری نتایج برای بهبود مداوم مدلها
با این رویکرد، تحلیل خودکار متون فارسی و انگلیسی در اتوماسیون گردش کار اسناد قابل استقرار و مقیاسپذیر است و ارزش اطلاعات استخراجشده را برای کسبوکارها به حداکثر میرساند.
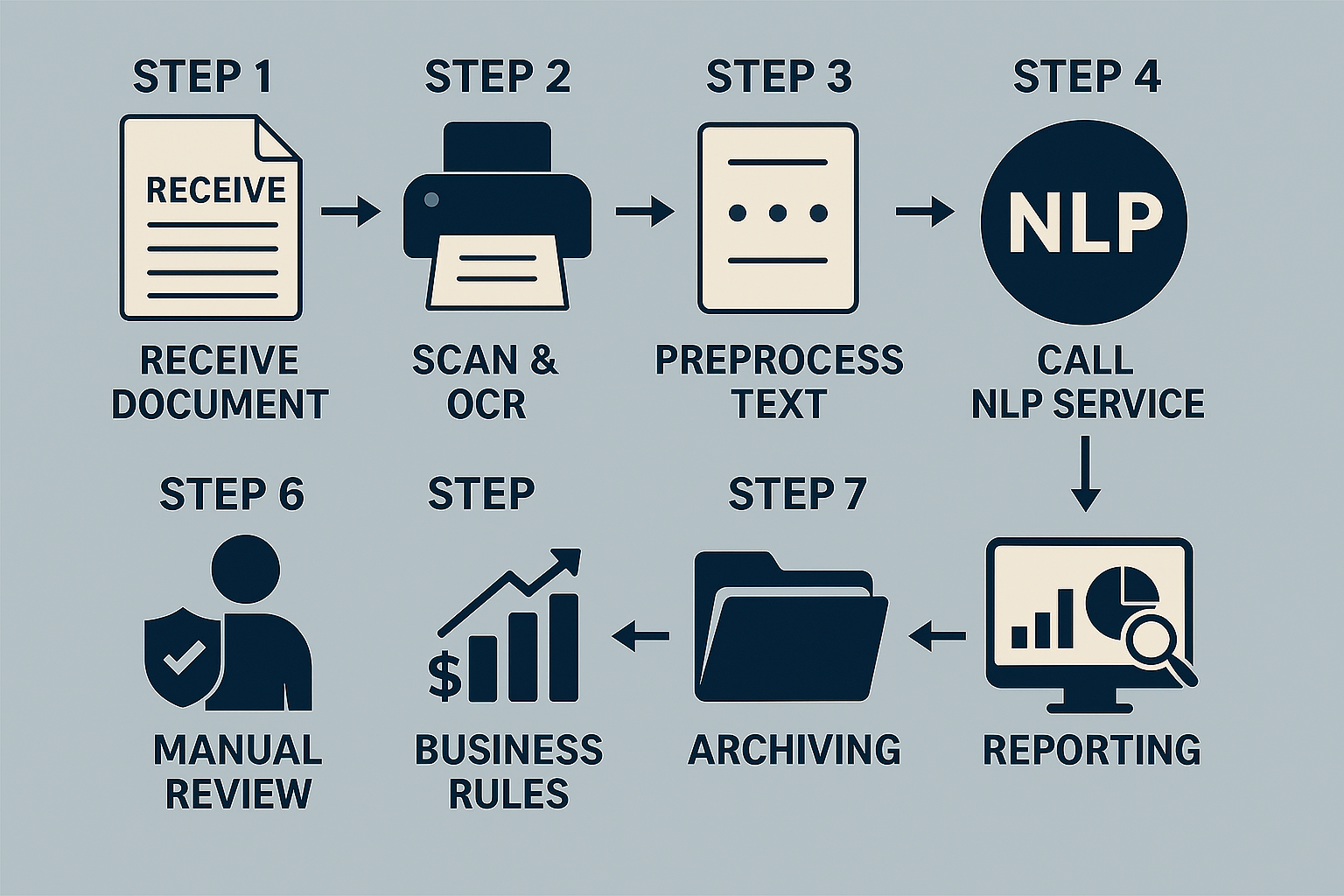
۵. تلفیق RPA و NLP 🔄
معماری یکپارچه: از دریافت سند تا ذخیرهسازی
-
ورودی سند
دریافت انواع سند (PDF، تصویر، ایمیل) توسط رباتهای RPA و ثبت در صف ورودی. - استخراج اولیه با OCR
رباتها سند را اسکن و متن خام را استخراج میکنند. - پیشپردازش متن
حذف نویسههای غیرضروری، نرمالسازی حروف و آمادهسازی برای تحلیل زبان طبیعی. - فراخوانی سرویس NLP
ارسال متن پاکسازیشده به یک REST API NLP جهت انجام NER، POS Tagging و تحلیل احساسات. - دریافت نتایج تحلیل
ساختار JSON حاوی موجودیتهای شناساییشده، برچسب موضوعی و احساسات برگشت داده میشود. - اجرای قواعد کسبوکار با RPA
براساس خروجی NLP، رباتهای RPA جریانهای متناسب (ارسال برای تأیید، ارجاع خودکار، یا صدور هشدار) را راهاندازی میکنند. - بازبینی و تأیید
در صورت نیاز، سند و دادههای استخراجی به کارتابل الکترونیک برای تأیید نهایی ارسال میشوند. - ذخیرهسازی نهایی
انتقال سند و متادیتا به مخزن دیجیتال (DB یا DMS) با فرمتهای قابل جستجو (PDF/A، XML). - گزارش و مانیتورینگ
ثبت لاگ هر مرحله و ارائه داشبورد KPI (زمان گردش، تعداد ارجاعات مجدد، دقت استخراج).
فلوچارت مرحله به مرحله 📈
+------------------+
| 1. دریافت سند |
+--------+---------+
|
v
+--------+---------+
| 2. اسکن و OCR |
| با RPA |
+--------+---------+
|
v
+--------+---------+
| 3. پیشپردازش |
| متن |
+--------+---------+
|
v
+--------+---------+
| 4. ارسال به NLP |
| (REST API) |
+--------+---------+
|
v
+--------+---------+
| 5. دریافت نتایج |
| تحلیل |
+--------+---------+
|
v
+--------+---------+
| 6. اجرای قواعد |
| کسبوکار |
| با RPA |
+--------+---------+
|
+-----+-----+
| |
v v
+------+ +--------+
| تأیید | | ارجاع |
| انسانی| | خودکار|
+---+--+ +---+----+
| |
+------+------+
|
v
+----------+---------+
| 7. ذخیرهسازی نهایی |
+---------------------+
|
v
+----------+---------+
| 8. گزارش و |
| مانیتورینگ |
+--------------------+
با استفاده از این معماری یکپارچه، میتوانید از قدرت RPA برای چابکی و از دقت NLP برای درک معنای متون بهرهمند شوید و اتوماسیون گردش کار اسناد را به سطح کاملاً هوشمند برسانید.
۶. مثال عملی: پیادهسازی در یک شرکت خدمات مالی 💼
ابزارها و فناوریهای مورد استفاده
- UiPath برای طراحی و اجرای رباتهای RPA
- ABBYY FlexiCapture برای OCR و استخراج اولیه
- ParsBERT (مدل Transformer) برای تحلیل متون فارسی
- spaCy و Hugging Face Transformers برای متون انگلیسی
- REST API اختصاصی برای فراخوانی سرویس NLP
- Microsoft SQL Server یا Elastic Search برای بایگانی دیجیتال
- Power BI برای داشبورد گزارشگیری و مانیتورینگ
مراحل پیادهسازی اتوماسیون گردش کار اسناد
- تحلیل گردش کار فعلیمصاحبه با واحد اعتبارسنجی و امور مشتریان برای شناسایی مراحل دستی و نقاط ضعف.
- راهاندازی اسکن و OCRاسکن خودکار صورتحسابها و مدارک KYC با ABBYY و استخراج متن خام.
- پیشپردازش و پاکسازی دادهنرمالسازی حروف، حذف نویسههای اضافی و اصلاح اشتباهات املایی با اسکریپتهای Python.
- فراخوانی سرویس NLPارسال متن پاکشده به REST API ParsBERT برای شناسایی موجودیتهای مالی (شماره حساب، نام مشتری، تاریخ تراکنش).
- تعریف رباتهای RPAپیادهسازی ربات UiPath برای خواندن خروجی NLP و پر کردن فرمهای تحت وب یا انتقال اطلاعات به CRM داخلی.
- ادغام و مسیریابی خودکاربراساس نتایج تحلیل، اسناد به واحد حسابرسی، اعتبارسنجی یا بایگانی دیجیتال مسیریابی میشوند.
- بازبینی دستی و بایگانیسند نهایی با امضای دیجیتال مدیر اعتبارسنجی تأیید و در مخزن SQL یا Elastic ذخیره میگردد.
- گزارشگیری و بهینهسازیPower BI شاخصهایی مانند متوسط زمان پردازش و نرخ خطا را نمایش میدهد و تیم IT بهصورت مستمر رباتها را بهبود میبخشد.
نتایج حاصل از پیادهسازی
| شاخص | قبل از اتوماسیون | بعد از اتوماسیون | بهبود |
|---|---|---|---|
| متوسط زمان پردازش هر پرونده | ۱۲۰ دقیقه | ۳۰ دقیقه | ۷۵٪ کاهش |
| نرخ خطای استخراج اطلاعات | ۸٪ | ۱٪ | ۷ درصد کاهش |
| هزینه نیروی انسانی ماهانه | ۲۰۰ میلیون تومان | ۶۰ میلیون تومان | ۷۰٪ کاهش |
| زمان بازگشت سرمایه (ROI) | — | ۳ ماه | — |
| درصد انطباق با مقررات مالی | ۹۰٪ | ۹۹٫۵٪ | ۹٫۵ درصد افزایش |
با این پیادهسازی، شرکت خدمات مالی موفق شد با اتوماسیون گردش کار اسناد سطح جدیدی از سرعت، دقت و انطباق با فرایندهای قانونی را تجربه کند و منابع انسانی خود را به تحلیلهای استراتژیکتر اختصاص دهد.
7. نتیجهگیری و فراخوان به اقدام (CTA) 🚀
اتوماسیون گردش کار اسناد با ترکیب RPA و NLP نشان داد که میتواند زمان پردازش را تا ۷۵٪ کاهش دهد، دقت استخراج اطلاعات را به بالای ۹۹٪ برساند و هزینههای عملیاتی را تا ۷۰٪ کم کند. این راهکار در عین افزایش شفافیت و پاسخگویی، امکان مقیاسپذیری و انطباق با مقررات مالی را نیز فراهم میآورد.
برای مشاهده مقالات مرتبط بر روی عنوان کیلیک کنید:
اتوماسیون چاپ و اسکن در دفاتر: حذف فرآیندهای دستی با ادغام OCR و RPA
چاپ بستهبندی هوشمند با فناوری NFC؛ شفافیت زنجیره تأمین و تجربه مشتری را متحول کنید
مدیریت چرخه حیات و خدمات پس از فروش تجهیزات اداری: کلید موفقیت اقتصادی کسبوکار
چاپ با نانوتکنولوژی: انقلاب در کیفیت و کارایی ماشینهای اداری
ماشینهای اداری سازگار با محیط زیست ؛ بررسی فناوریهای کاهش مصرف انرژی و مواد مصرفی✅
پرینترهای هوشمند آینده؛ فناوریهای نوین در چاپ دیجیتال”
پرینترجوهرافشان: فناوری، کاربردها و مزایای آنها 🖨️✨
پرینتر لیزری: راهنمای جامع ،عملکرد، مزایا و نکات خرید 🖨️✨
ماشین اداری هوشمند،نقش هوش مصنوعی در ماشینهای اداری 🤖
 “این مقاله با همکاری دستیار هوشمصنوعی Microsoft Copilot تهیه شده است که اطلاعات را با دقت و جامعیت بالا گردآوری کرده است.”
“این مقاله با همکاری دستیار هوشمصنوعی Microsoft Copilot تهیه شده است که اطلاعات را با دقت و جامعیت بالا گردآوری کرده است.”



برای نوشتن دیدگاه باید وارد بشوید.